
A team of psychologists and AI experts led by the University of Cambridge applied some of the top generative AI models to grade hundreds of undergraduate essays and found that AI only matched human-awarded broad grading classifications about half the time, often failing to identify the best and worst submissions accurately.
The researchers tested three “frontier” systems – Claude Opus 4.6, GPT-5.4 and Gemini 3 Flash – on over 750 student essays from three UK universities submitted as part of a psychology degree.
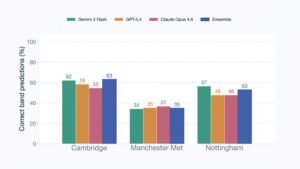
The researchers found that AI accuracy in grading essays varied across coursework and exam answers. It managed to match the broad grading categories given by human examiners, such as a First, 2:1 and 2:2, around 35-65% of the time.
However, the study revealed that AI routinely undervalued work awarded top marks by humans, or overvalued essays ranked among the lowest.
The researchers warned that relying heavily on AI for assessment could lead to “homogenised” grading that “underestimates brilliance”.
“Unlike human examiners, all the AI systems were “oversensitive to linguistic features”: giving out higher marks based on essay length, vocabulary range and sentence complexity, which are often unrelated to academic standards,” the report stated.
According to the latest report titled “AI in University Assessment: Evaluating the Opportunities and Risks of Automated Marking”, the accuracy and validity of AI systems are not yet sufficiently robust to support students and educators.
The findings indicated that accuracy and validity vary across contexts, with discrepancies at grade boundaries and for the highest and lowest performing submissions.
The study suggested that deploying AI systems for assessment should be conditional on evidence of stability, alignment with human judgement, and the absence of systematic bias, to ensure fairness and maintain academic standards.
The team cautioned that AI alone is far too shallow and inconsistent to grade undergraduate work, and a human should always determine the final mark.
“Universities are under huge pressure to reduce staff workload and improve efficiency, all while meeting rising student expectations, and some may start to lean on AI for assessment,” said Dr Deborah Talmi, the Cambridge psychologist who leads the OpRaise project behind the new report.
“We find that leaning heavily on the best current AI models would see student grading that is homogenised, underestimates brilliance, and favours linguistic style over the substance of sound academic judgement,” she said.
The report, ‘AI in University Assessment: Evaluating the Opportunities and Risks of Automated Marking’, is supported by ai@cam, Cambridge University’s flagship mission to develop AI for the benefit of society, and the Accelerate Programme for Scientific Discovery, made possible by a donation from Schmidt Sciences. It was launched at an event with the British Psychological Society.
University staff and students who took part in the study told researchers that, while current assessment practices are not perfect, being graded and receiving feedback from humans is fundamental to the “social contract” between academics and students.
“Many students said they would feel cheated if AI marked their work, and staff warned that relying on AI risks weakening trust, motivation, professional judgement, and the human engagement at the heart of higher education,” said Dr Yael Benn, a collaborator on the project from Manchester Metropolitan University.
The study used 761 undergraduate essays in psychology submitted and marked between 2022 and 2025 from a total of 125 students from the universities of Cambridge, Manchester Metropolitan and Nottingham. The researchers chose to focus on psychology as essays are central to degree results in the subject.
Researchers tested AI systems with the same essays at different times and found AI gave the same or similar marks each time. They found that different AI models were much closer to each other than to humans in their marking.
The researchers suspected that the difference in AI accuracy across institutions is due to the range of grades, which was narrowest among Cambridge students, whose essays were all written in invigilated exam halls, and widest at Manchester Metropolitan, where all analyzed essays were coursework. Nottingham essays were a mixture of both.
“Human assessors judge each essay on its own argumentative and conceptual merits while AI marks are based on statistical predictions,” said co-author Dr Alexandru Marcoci, from Cambridge’s Institute for Technology and Humanity.
Also Read: Australia’s Classroom AI Crisis: Cheating, Learning Loss and No Easy Fix









