
A new Stanford study assessed six commercial AI chatbots using 2,100 same-day news questions, generating 12,600 model responses across six regions and languages.
Researchers conducted the evaluation over 14 days (February 9–22, 2026) using same-day BBC News questions from six regional services: U.S. & Canada, Afrique, Arabic, Hindi, Russian and Turkish.
The study, titled “Reading Today’s Headlines Through AI: A Real-Time Audit of Six Commercial Chatbots”, examined how leading AI systems perform when answering questions about current news events.
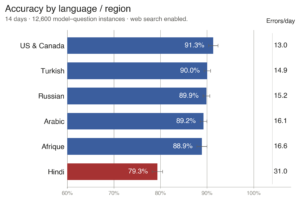
According to the study, top performing models such as Gemini 3 Flash, Grok 4 and Gemini 3 Pro answered correctly more than nine times out of ten. They achieved an accuracy rate of more than 90%.
However, researchers said the strong overall scores obscured three key patterns: a significant performance gap on Hindi-language content, differences in citation and source-selection patterns across chatbots, and weaker performance when questions contained inaccurate assumptions.
The study also identified significant disparities across languages and regions. Hindi-language questions recorded the lowest average accuracy at 79.3%, nearly 10% points below the next-lowest region.
“Every model tested performed the worst in Hindi,” the study said.
Researchers attributed the gap not to language comprehension but to failures in retrieving relevant Hindi-language sources. Retrieval failure accounted for 38.8% of errors, while source divergence, in which models retrieved a thematically related but factually different source, accounted for 32.7%.
“The failure is not one of language comprehension. These systems read Hindi fluently and reason competently in it. It is a failure of evidence binding,” the study highlighted. It further stressed that chatbots often relied on English-language sources covering similar news topics, leading to inaccurate answers.
The researchers also analyzed every URL cited across all 12,600 model responses and found significant differences in citation patterns across chatbots. The study said these differences likely reflect a combination of retrieval systems, licensing arrangements and source-access policies, potentially influencing which information reaches users.
Second, the study found that models relied heavily on English-language sources even when answering questions about non-English news. “Of the six BBC regional services we evaluated, only the U.S. & Canada publishes in English,” the study said.
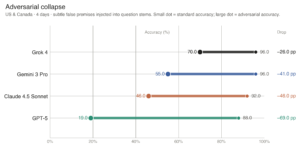
The study also found that chatbot performance deteriorated when questions contained misleading or inaccurate premises. In adversarial testing, Grok 4 retained 70% accuracy while GPT-5 fell to 19%, highlighting significant differences in how models handled flawed user queries.
Citing a 2026 Reuters Institute survey, the study noted that news executives expect a 43% decline in Google search traffic to publishers over the next three years.
“As more users encounter journalism through AI lenses rather than directly through publishers’ sites, differences in retrieval, attribution, and source selection will increasingly shape whose reporting reaches the general public, under what terms, and how,” the study stated.
According to the study, around 10% of Americans already use AI chatbots for news at least occasionally, while the figure approaches 15% among news consumers under 25 globally.
Also Read: NYT Publisher: ‘Tech Giants Strip-Mine Original Journalism, Repackage Stolen Goods as Their Own’





